Pre-warming Container Images on Upgraded Nodes with Kubernetes CronJob + DaemonSet
The Problem
On our hosted notebook platform, when a node undergoes an OS upgrade, it rejoins the cluster with a fresh slate — no cached container images. The first user pod scheduled on that node pays the full image pull penalty for the base image, leading to slow startup times and a degraded experience.
We needed a way to guarantee that upgraded nodes have the base image pre-warmed before any user workload lands on them.
Why Not Just Let It Pull?
Our base images are large. A cold pull on a freshly upgraded node adds significant latency to the first notebook spawn. In a platform where users expect near-instant startup, that delay is noticeable. The image needs to be ready before the node is open for scheduling.
The Alternative: A Custom Controller
The textbook Kubernetes answer would be a custom controller (operator) that watches node events and reacts in real-time.
How It Would Work
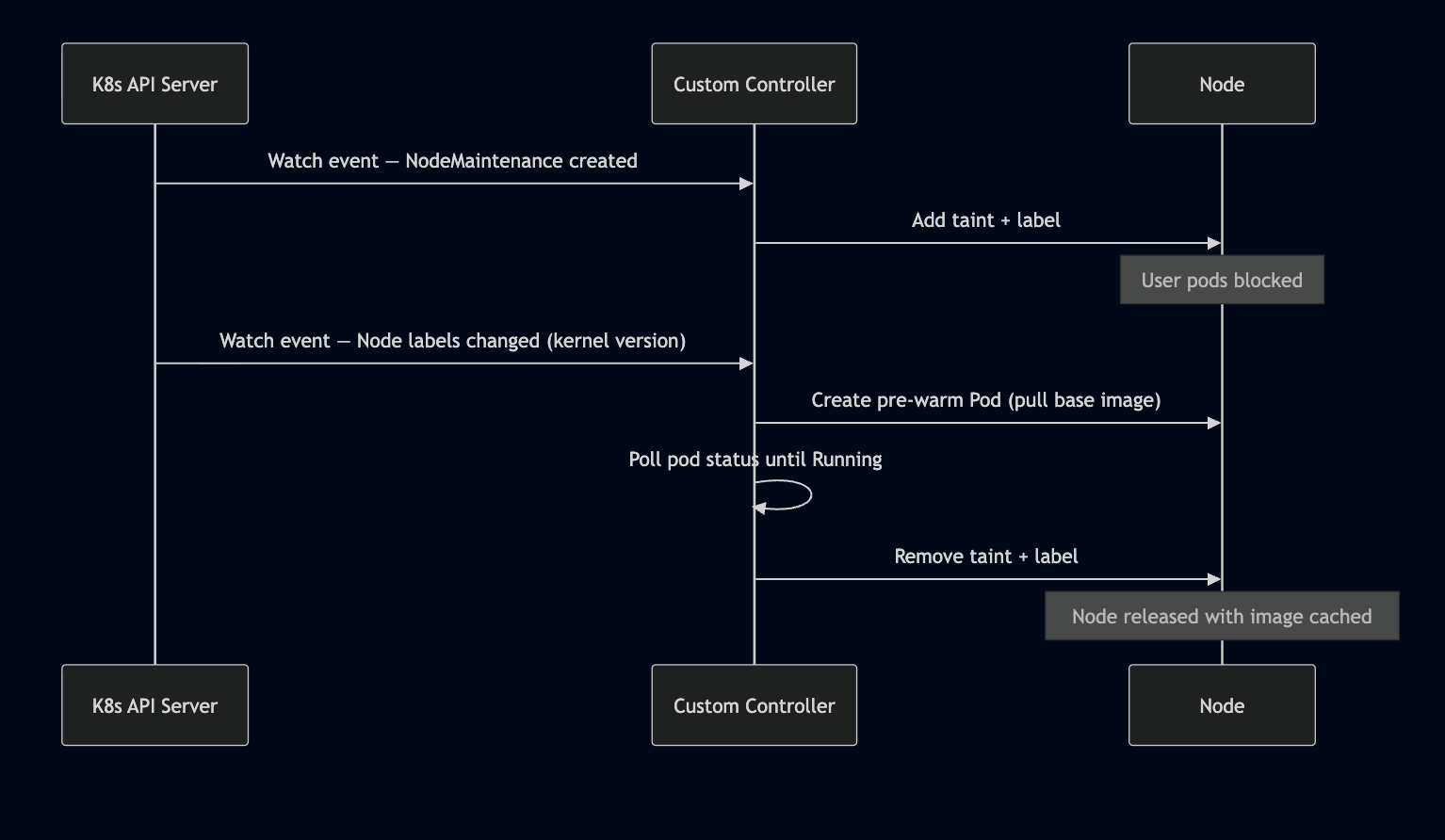
The controller would use the watch/reconcile pattern — subscribe to node events via the K8s API, react to label changes in near real-time, and manage the full lifecycle in a single reconciliation loop.
Why We Didn’t Go This Route
| Concern | Custom Controller | CronJob + DaemonSet |
|---|---|---|
| React time | Seconds (event-driven) | Up to 1 hour (poll-based) |
| Complexity | Custom CRD, RBAC, leader election, error handling | Two standard K8s resources + a script |
| Maintenance | Dedicated codebase, CI/CD, versioning | ConfigMap with a Python script |
| Failure mode | Controller crash = no nodes processed | Missed cycle = next run catches up |
| Deployment | Needs a long-running Deployment with HA | CronJob is fire-and-forget |
| Development time | Weeks (with testing, CRD design) | Days |
For our use case — a batch of nodes upgrading over hours, not minutes — the near-instant reaction time of a controller wasn’t worth the operational overhead. The CronJob’s hourly poll is fast enough, and the DaemonSet gives us the per-node execution for free.
A custom controller becomes the right choice when you need sub-second reaction times, complex state machines, or this pattern extends to many different reconciliation workflows.
Our Approach: Taint, Upgrade, Pre-warm, Untaint
We broke the problem into two standard Kubernetes primitives working in concert — a CronJob as the orchestrator and a DaemonSet as the per-node executor.
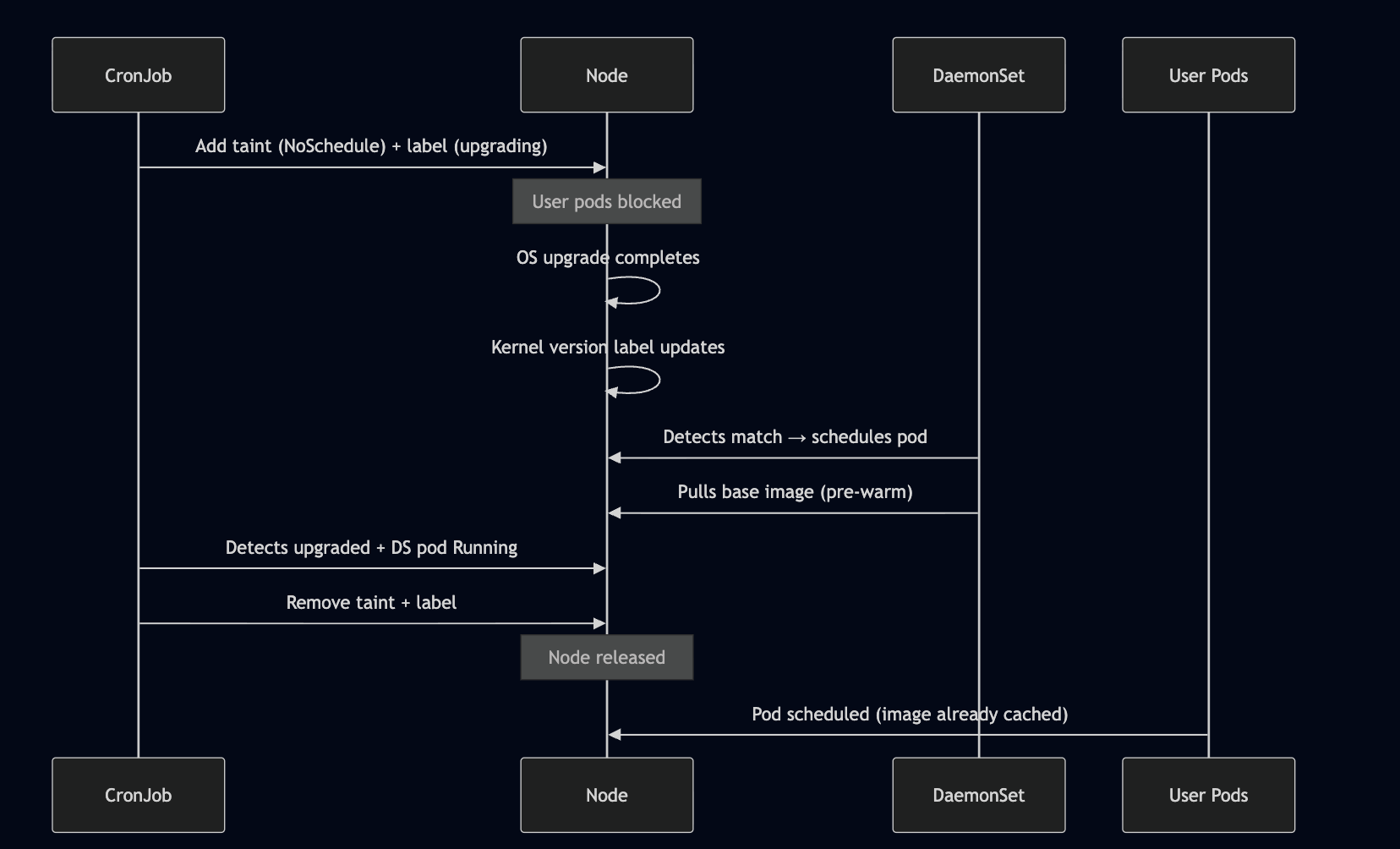
Component 1: The CronJob — Orchestrator
A CronJob runs every hour and executes a Python script with two responsibilities.
Part 1 — Taint & Label
Fetches all active node maintenance objects for the notebook pool. For each node, it applies:
- Label:
os-upgrade/status=upgrading - Taint:
os-upgrade=true:NoSchedule
The taint prevents any user pods from landing on the node. The label acts as a targeting signal for the DaemonSet.
apiVersion: batch/v1
kind: CronJob
metadata:
name: os-upgrade-orchestrator
namespace: notebooks
spec:
schedule: "0 * * * *"
jobTemplate:
spec:
backoffLimit: 2
ttlSecondsAfterFinished: 30
template:
spec:
restartPolicy: OnFailure
serviceAccountName: upgrade-sa
containers:
- name: orchestrator
image: my-registry/image-prewarmer:latest
command: ["/bin/sh", "-c", "python3 /scripts/orchestrate.py"]
volumeMounts:
- name: script
mountPath: /scripts/orchestrate.py
subPath: orchestrate.py
volumes:
- name: script
configMap:
name: upgrade-orchestrator-script
Part 2 — Detect & Release
On each run, the script also checks for nodes that have already been upgraded (by reading the kernel version label) AND have a Running DaemonSet pod. That intersection represents nodes where the upgrade is complete and the image is warm. For those nodes, the script removes the taint and label.
upgraded_nodes = fetch_upgraded_nodes()
nodes_with_running_ds_pod = fetch_running_daemonset_pods()
ready_nodes = set(upgraded_nodes) & set(nodes_with_running_ds_pod)
for node in ready_nodes:
remove_label_and_taint(node)
Component 2: The DaemonSet — Image Pre-warmer
A DaemonSet with tight node affinity targets only nodes satisfying all three conditions:
- Upgraded kernel — e.g.
kernel-version.full = 5.15.173.1 - Notebook pool — e.g.
node-pool = notebooks - Upgrade in progress —
os-upgrade/status = upgrading
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: image-prewarmer
namespace: notebooks
spec:
selector:
matchLabels:
app: image-prewarmer
template:
metadata:
labels:
app: image-prewarmer
spec:
tolerations:
- key: "os-upgrade"
operator: "Equal"
value: "true"
effect: "NoSchedule"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/kernel-version
operator: In
values: ["5.15.173.1"]
- key: node-pool
operator: In
values: ["notebooks"]
- key: os-upgrade/status
operator: In
values: ["upgrading"]
containers:
- name: warmer
image: my-registry/notebook-base:latest
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
command: ['sh', '-c', 'echo "Image pulled — pre-warm complete" && sleep 3600']
Key design choices:
- The DaemonSet tolerates the
os-upgradetaint — it can schedule where user pods cannot - The container image is the actual base image we want cached — pulling it is the pre-warming
- The container just sleeps — its only job is to trigger the pull and serve as a ready signal for the CronJob
Node Lifecycle Through an Upgrade
Why This Works Well
- Self-healing. The CronJob continuously reconciles. If a node is missed in one cycle, it gets picked up in the next.
- No user impact. The taint guarantees no user pod hits a cold node. The node only becomes schedulable after the image is confirmed cached.
- Native K8s primitives. DaemonSets naturally handle “run exactly one pod per matching node.” No custom controller needed — just the right combination of labels, taints, and affinity rules.
- Decoupled from the upgrade pipeline. We don’t modify the OS upgrade process. We observe its side effects (kernel version label change) and react.
Takeaway
Sometimes you don’t need a custom operator. A CronJob for orchestration + a DaemonSet for per-node work, connected through labels and taints, gave us a reliable image pre-warming pipeline with about 200 lines of Python and 90 lines of YAML. The custom controller path would have given us faster reaction times, but for a process that plays out over hours, polling every hour is more than adequate — and dramatically simpler to build, deploy, and maintain.